Inteligencia artificial
Como los Skills de Desarrollo de Opus 4.6 Imponen Buenas Practicas sin Eliminar la Revision Experta
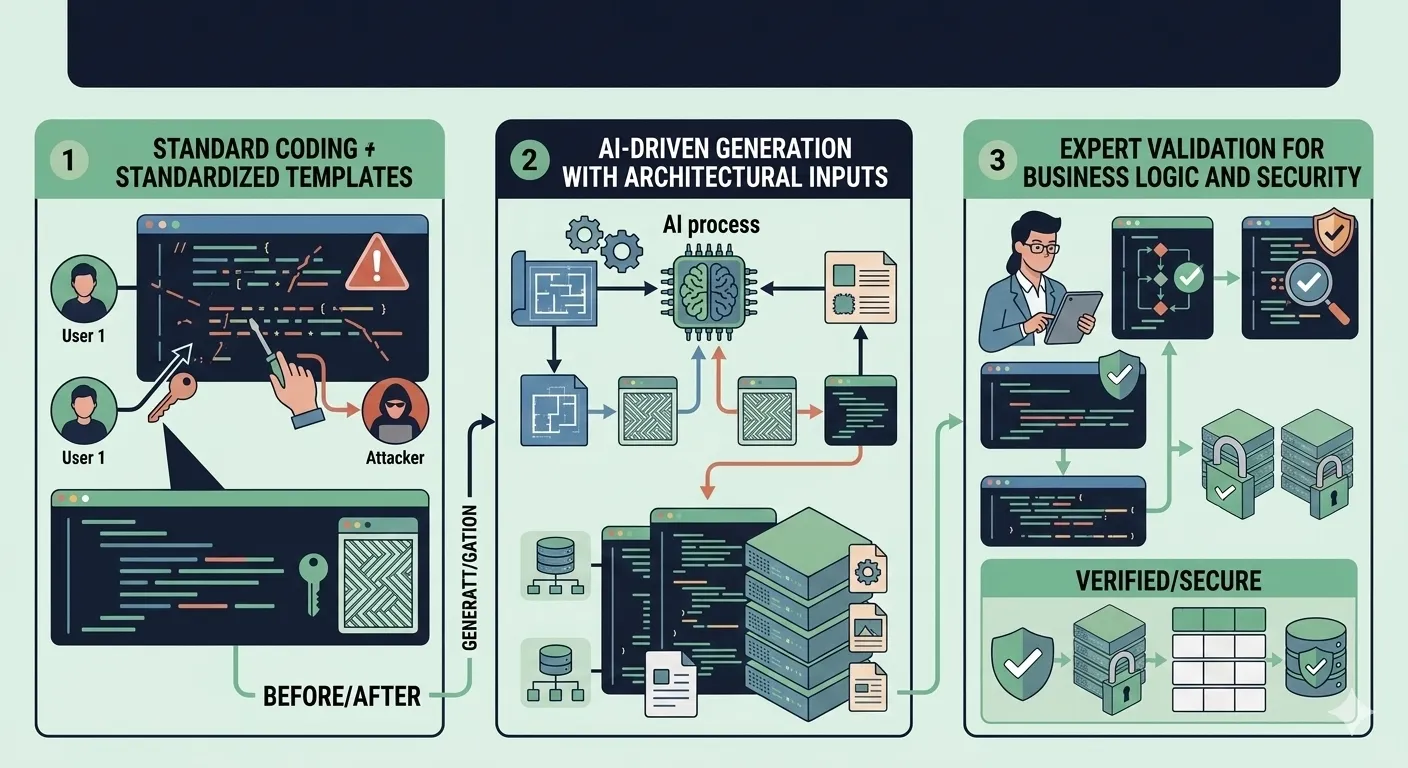
Existe una brecha cada vez mayor entre lo que la IA puede generar y lo que los sistemas en produccion realmente necesitan. Los modelos de lenguaje producen codigo sintacticamente correcto a una velocidad notable, pero la correccion sintactica no es lo mismo que la solidez arquitectonica. Una funcion que compila no es necesariamente una funcion que pertenece a tu codebase. Esta desconexion se vuelve peligrosa a escala, cuando docenas de archivos generados por IA se acumulan sin estructura consistente, convenciones de nomenclatura ni reglas de dependencia. Los skills de desarrollo resuelven este problema. Un skill es una plantilla de instrucciones reutilizable que restringe como un modelo de IA genera codigo, imponiendo patrones arquitectonicos especificos, reglas de organizacion de archivos y estandares de codificacion antes de que se escriba una sola linea. Con Opus 4.6, estos skills alcanzan un nuevo nivel de efectividad porque la capacidad del modelo para seguir instrucciones maneja restricciones complejas y multinivel sin descartar reglas silenciosamente. Pero los skills no reemplazan la experiencia humana. Manejan los aspectos estructurales y mecanicos de la generacion de codigo mientras liberan a los desarrolladores expertos para enfocarse donde aportan valor irremplazable: correccion de logica de negocio, validacion de limites de seguridad y casos extremos especificos del dominio.
Que son los Skills de Desarrollo en la Programacion Asistida por IA
Un skill de desarrollo es un documento estructurado que indica a un modelo de IA exactamente como generar codigo para un contexto especifico. A diferencia de un prompt casual que dice "construyeme una API REST," un skill define las capas arquitectonicas, las convenciones de nomenclatura de archivos, las reglas de direccion de dependencias, los patrones de manejo de errores y las estrategias de validacion que el codigo generado debe seguir. Piensa en ello como un documento de estandares de codificacion que la IA lee y aplica en tiempo real, cada vez que genera salida.
La diferencia entre el prompting directo y la generacion guiada por skills es la repetibilidad. Cuando le pides a un modelo de IA que "cree una API Node.js con autenticacion de usuarios," obtienes una estructura diferente cada vez. Una ejecucion puede poner todo en un unico archivo app.js. La siguiente podria crear una estructura de carpetas que vagamente se asemeja a MVC. Una tercera podria mezclar middleware de Express con logica de negocio en la misma funcion. Los skills eliminan esta varianza codificando decisiones que nunca deben cambiar entre ejecuciones: donde van los archivos, como se comunican las capas, que patrones son obligatorios.
Anatomia de un Skill Bien Escrito
Un skill efectivo contiene varias secciones distintas que trabajan juntas para restringir la salida de la IA. La seccion de restricciones define reglas innegociables: una clase por archivo, sin dependencias circulares, interfaces definidas antes que implementaciones. La seccion de patrones especifica que patrones de diseno aplicar: CQRS para separacion de comandos y consultas, patron repositorio para acceso a datos, pipeline de middleware para preocupaciones transversales. Las reglas de validacion dictan donde ocurre la validacion de entrada (capa de Application, nunca Domain) y que bibliotecas utilizar. La seccion de formato de salida especifica convenciones de nomenclatura de archivos, estructura de directorios y patrones de exportacion.
Opus 4.6 maneja estos skills multinivel con particular fidelidad. Los modelos anteriores seguian las primeras restricciones y gradualmente se desviaban a medida que la salida crecia. La ventana de contexto extendida de Opus 4.6 y su adherencia mejorada a instrucciones significan que puede mantener el cumplimiento con mas de 30 reglas a traves de miles de lineas de codigo generado sin descartar silenciosamente restricciones a mitad de la generacion.
Por Que el Prompting Directo Falla a Escala
El problema de inconsistencia es el mayor obstaculo individual para adoptar la generacion de codigo con IA en equipos profesionales. Cuando un desarrollador formula el prompt con palabras ligeramente diferentes, la estructura de salida cambia. Cuando el mismo desarrollador formula el prompt identicamente en dias diferentes, la temperatura del modelo y las diferencias de contexto producen variaciones. En semanas, un codebase ensamblado a partir de prompts directos de IA se convierte en un mosaico de patrones conflictivos, nomenclatura inconsistente y dependencias enredadas.
Un error comun que cometen los desarrolladores es confiar en la salida de IA sin estructura ni protecciones. Ven un endpoint funcionando y asumen que la arquitectura subyacente es solida. Pero "funciona" y "es mantenible" son estandares diferentes. Un endpoint que retorna JSON correcto hoy pero viola la inversion de dependencias se convertira en una pesadilla de refactorizacion cuando la fuente de datos cambie. Un middleware de autenticacion que mezcla logica de autorizacion con gestion de sesiones creara puntos ciegos de seguridad que ninguna cantidad de testing detecta facilmente.
Consideremos un escenario real: un equipo de ocho desarrolladores adopta la codificacion asistida por IA sin establecer skills compartidos. El desarrollador A genera servicios que retornan entidades de base de datos directamente. El desarrollador B genera servicios que mapean a DTOs. El desarrollador C genera servicios que lanzan excepciones HTTP desde la capa de dominio. En dos sprints, el codebase tiene tres patrones incompatibles para la misma operacion. Las revisiones de codigo se convierten en cuello de botella porque cada pull request requiere discusion arquitectonica que debio haberse resuelto antes de comenzar la generacion.
El Costo de la Inconsistencia en Produccion
La arquitectura inconsistente no es solo un problema estetico. Crea costos medibles de rendimiento y escalabilidad. Cuando diferentes modulos manejan errores de manera diferente, los sistemas de monitoreo no pueden agregar patrones de fallo de forma confiable. Cuando algunos servicios usan connection pooling y otros crean nuevas conexiones por solicitud, el rendimiento de la base de datos se degrada impredeciblemente bajo carga. Cuando la validacion ocurre en diferentes capas segun el modulo, las vulnerabilidades de seguridad se agrupan en los limites donde las suposiciones cambian. Solo la carga de revision puede reducir la velocidad de entrega entre un 30-50%, ya que los desarrolladores senior gastan mas tiempo corrigiendo problemas estructurales que evaluando logica de negocio.
Construyendo un Skill de Clean Architecture para Node.js: Ejemplo Practico
Recorramos un skill concreto que instruye a Opus 4.6 para generar un scaffolding de API REST en Node.js que impone clean architecture. Este skill codifica seis categorias de restricciones que juntas garantizan consistencia estructural en cada modulo generado.
El skill comienza con restricciones de estructura de archivos. Cada proyecto generado debe seguir un layout de directorios estricto con cuatro capas de nivel superior: domain/, application/, infrastructure/ y api/. Cada capa tiene sus propios subdirectorios para entidades, casos de uso, repositorios y controladores respectivamente. La regla es absoluta: una clase por archivo, un archivo por responsabilidad, sin excepciones para DTOs, comandos ni interfaces.
A continuacion, las reglas de direccion de dependencias imponen que las importaciones solo fluyan hacia adentro. La capa api/ puede importar de application/, pero application/ nunca importa de api/. La capa domain/ no importa nada de ninguna otra capa. Esto se valida estructuralmente: si la IA genera una sentencia import que viola esta regla, el skill le instruye a refactorizar inmediatamente usando inyeccion de dependencias.
El diseno interface-first requiere que cada repositorio, servicio externo y fuente de datos se defina como interfaz en la capa domain/ o application/ antes de que exista cualquier implementacion. Las implementaciones viven exclusivamente en infrastructure/. Esto garantiza que la logica de negocio nunca se acople a bases de datos especificas, clientes HTTP ni servicios de terceros.
El skill impone patron CQRS con separacion de handlers: cada operacion de escritura es un Command con un CommandHandler dedicado, cada operacion de lectura es un Query con un QueryHandler dedicado. Los Commands retornan objetos Result, nunca entidades directas. Los handlers son el unico lugar donde ocurre la orquestacion de casos de uso.
Las reglas de validacion especifican que toda validacion de entrada usa schemas Zod definidos en la capa Application. Las entidades de dominio imponen sus propias invariantes a traves de validacion en el constructor, pero el parsing de entrada externa nunca es responsabilidad del Domain. Las respuestas de error siguen un formato de envolvente estandarizado.
Finalmente, los patrones de manejo de errores definen una jerarquia personalizada: DomainError, ApplicationError, InfrastructureError. Cada capa captura y envuelve errores de capas internas, agregando contexto sin exponer detalles de implementacion. La capa API tiene un unico middleware de manejo de errores que mapea tipos de error a codigos de estado HTTP.
Salida del Skill vs. Salida del Prompting Directo
La diferencia estructural es inmediatamente visible. Al generar una funcionalidad de registro de usuarios, la salida guiada por skill produce esta estructura de directorios:
src/
domain/
entities/
User.js
interfaces/
IUserRepository.js
errors/
DomainError.js
application/
commands/
CreateUser/
CreateUserCommand.js
CreateUserHandler.js
validation/
createUserSchema.js
errors/
ApplicationError.js
infrastructure/
repositories/
UserRepository.js
errors/
InfrastructureError.js
api/
controllers/
UserController.js
middleware/
errorHandler.js
routes/
userRoutes.jsEl mismo prompt sin skill tipicamente produce una estructura plana con dos a cuatro archivos: un archivo de rutas, un controlador que contiene tanto validacion como consultas a base de datos, y quizas un archivo de modelo que mezcla definicion de schema con logica de negocio. La salida guiada por skill es inmediatamente revisable porque los revisores saben exactamente donde buscar cada responsabilidad.
El Punto de Control de Revision Experta
Un skill bien disenado no pretende reemplazar el juicio humano. En cambio, marca explicitamente los limites donde la revision humana es esencial. El skill instruye a la IA para dejar marcadores // REVIEW: business rule donde la logica especifica del dominio requiere validacion por alguien que comprenda el contexto de negocio. De manera similar, los marcadores // REVIEW: security boundary aparecen en verificaciones de autenticacion, puertas de autorizacion y puntos de sanitizacion de datos.
Este modelo hibrido supera tanto al enfoque completamente manual como al completamente automatizado. El desarrollo manual completo es mas lento pero detecta todo. El desarrollo completamente con IA es rapido pero pierde los matices del dominio. El enfoque guiado por skills permite que la IA maneje el 60-70% del codigo que es scaffolding estructural mientras concentra la atencion experta en el 30-40% que requiere conocimiento de negocio, conciencia de seguridad y razonamiento sobre casos extremos.
Comparacion: Desarrollo con IA Con y Sin Skills
La siguiente tabla resume las diferencias medibles entre el prompting directo y el desarrollo guiado por skills en las dimensiones que mas importan a los equipos de ingenieria:
| Aspecto | Prompting Directo | Generacion Guiada por Skill |
|---|---|---|
| Consistencia arquitectonica | Baja — varia por prompt y sesion | Alta — impuesta por restricciones del skill |
| Carga de revision de codigo | Alta — revisores verifican todo | Moderada — revisores se enfocan en logica |
| Adherencia a patrones | Inconsistente entre desarrolladores | Uniforme en todo el equipo |
| Alcance de la revision experta | Cada linea, incluyendo boilerplate | Solo logica de negocio y casos extremos |
| Onboarding de nuevos desarrolladores | Lento — deben aprender convenciones implicitas | Rapido — el skill documenta la arquitectura |
| Violaciones de reglas de dependencia | Frecuentes y dificiles de detectar | Prevenidas en tiempo de generacion |
| Costo de refactorizacion | Alto — fundamentos inconsistentes | Bajo — estructura uniforme en todo el codigo |
Solo la reduccion de carga de revision justifica la inversion en escribir skills. Cuando los revisores confian en que la estructura de archivos, las convenciones de nomenclatura y las direcciones de dependencia son correctas por construccion, pueden dedicar toda su atencion a las preguntas que genuinamente requieren juicio humano: ¿Esta regla de negocio cubre todos los casos extremos? ¿Es suficiente esta verificacion de autorizacion? ¿Esta consulta tiene rendimiento aceptable bajo la carga proyectada?
Cuando los Skills No Son la Respuesta Correcta
Los skills agregan overhead que no siempre se justifica. Para prototipado rapido, cuando necesitas validar una idea en horas en lugar de dias, el prompting directo es mas veloz. El codigo generado es desechable, asi que la consistencia arquitectonica no importa. De manera similar, los scripts de uso unico para migracion de datos, analisis de logs o configuracion de entornos no se benefician de restricciones de skills porque se ejecutan una vez y se descartan. Los spikes de investigacion, donde estas explorando una API o biblioteca desconocida para entender su comportamiento, se benefician mas de la iteracion conversacional que de restricciones estructurales. La regla es directa: usa skills cuando el codigo generado vivira en un codebase compartido y enfrentara mantenimiento continuo.
La Capa de Revision Experta: Por Que No Se Puede Eliminar
Los skills garantizan estructura, convencion y correccion mecanica. Imponen que los archivos vayan en los directorios correctos, que las importaciones fluyan en la direccion correcta, que los handlers sigan el patron prescrito. Lo que no pueden garantizar es si el codigo hace lo correcto en un contexto de negocio.
Consideremos un escenario arquitectonico en una API fintech que procesa conversiones de moneda. El skill genera correctamente un ConvertCurrencyHandler con estructura CQRS apropiada, validacion Zod, interfaces de repositorio y manejo de errores. El codigo generado redondea los resultados de conversion a dos decimales usando aritmetica de punto flotante estandar de JavaScript. Esto es estructuralmente perfecto y logicamente incorrecto. Las reglas de redondeo de moneda varian segun la divisa: el yen japones usa cero decimales, el dinar kuwaiti usa tres, y ciertos calculos interbancarios requieren cinco. El skill no puede codificar este conocimiento porque es logica de negocio especifica del dominio que cambia por cliente, por jurisdiccion regulatoria y por linea de producto.
Los casos extremos de seguridad presentan el mismo desafio. Un skill puede imponer que el middleware de autenticacion exista en cada ruta protegida. No puede determinar si la logica de autorizacion maneja correctamente la herencia de roles, los permisos de acceso temporal, o las reglas de negocio especificas sobre acceso a datos que difieren entre organizaciones. Estas decisiones requieren a alguien que comprenda el modelo de amenazas, los requisitos de cumplimiento y el contexto operacional del sistema desplegado.
Disenando Puntos de Control de Revision en Tus Skills
Los skills mas efectivos integran explicitamente marcadores de revision que guian a los revisores humanos hacia las decisiones que requieren su experiencia. En lugar de dejar que los revisores escaneen cada archivo, el skill instruye a la IA para insertar marcadores especificos:
// REVIEW: business rule— aparece donde la logica especifica del dominio determina el comportamiento de salida, como calculos de precios, verificaciones de elegibilidad o transiciones de flujo de trabajo.// REVIEW: security boundary— aparece en puertas de autenticacion, decisiones de autorizacion, puntos de sanitizacion de datos y donde datos sensibles cruzan un limite de confianza.// REVIEW: external integration— aparece en configuraciones de clientes API, politicas de reintentos, valores de timeout y manejo de rate limiting donde las suposiciones operacionales deben validarse.// REVIEW: data model assumption— aparece donde el codigo generado asume una forma de datos especifica, cardinalidad de relacion o campo nullable que el experto del dominio debe confirmar.
Los equipos que adoptan este patron reportan reducir los ciclos de revision entre un 40-60% en temas estructurales. Los revisores ya no gastan tiempo verificando ubicacion de archivos, convenciones de nomenclatura o direcciones de importacion. Navegan directamente a los marcadores REVIEW y evaluan unicamente las decisiones que genuinamente requieren experiencia humana.
Capacidades de Opus 4.6 que Hacen Efectivos a los Skills
No todo modelo de IA puede ejecutar skills complejos de manera confiable. La efectividad de un skill depende de la capacidad del modelo para mantener el cumplimiento de restricciones a traves de salidas largas, seguir instrucciones condicionales anidadas y producir salida estructurada que coincida con especificaciones precisas. Opus 4.6 aporta tres capacidades que impactan directamente la calidad de ejecucion de skills.
Primero, el procesamiento de contexto extendido significa que el modelo puede mantener la definicion completa del skill, el contexto del codebase existente y el objetivo de generacion en memoria simultaneamente. Cuando un skill referencia un archivo generado anteriormente en la misma sesion, Opus 4.6 mantiene la consistencia sin desviaciones.
Segundo, la adherencia a instrucciones bajo complejidad es mediblemente mas fuerte. Los skills con mas de 20 reglas prueban la capacidad de un modelo para rastrear y aplicar multiples restricciones simultaneamente. En evaluaciones comparativas, Opus 4.6 mantiene el cumplimiento con conjuntos de reglas complejos a tasas significativamente mas altas que los modelos de generacion anterior, particularmente para reglas que interactuan entre si (por ejemplo, "validacion en capa Application" combinada con "sin importaciones de domain en infrastructure").
Tercero, la fiabilidad de salida estructurada asegura que el codigo generado siga patrones de formato, nomenclatura y organizacion especificados de manera consistente. Cuando un skill especifica PascalCase para clases, camelCase para funciones y kebab-case para nombres de archivos, Opus 4.6 aplica estas convenciones uniformemente en lugar de recurrir al patron mas comun en sus datos de entrenamiento.
Comparando Modelos de IA para Ejecucion de Skills
Las diferencias practicas entre modelos se hacen evidentes al ejecutar el mismo skill de clean architecture repetidamente. Opus 4.6 mantiene cumplimiento total de restricciones en ejecuciones repetidas, produciendo jerarquias de directorios estructuralmente identicas con nomenclatura, importaciones y patrones consistentes. GPT-4o sigue las restricciones estructurales principales adecuadamente pero ocasionalmente fusiona archivos relacionados (combinando un Command y su Handler en un archivo) o se desvia en convenciones de nomenclatura en salidas mas largas. Los modelos Gemini manejan la estructura de directorios de alto nivel pero tienen dificultades con reglas matizadas como la aplicacion de direccion de dependencias, generando a veces importaciones de capa infrastructure en handlers de capa application. El diferenciador clave no es si un modelo puede seguir instrucciones simples, sino si sostiene el cumplimiento con restricciones complejas e interactuantes en salidas que superan las 500 lineas.
Preguntas Frecuentes
¿Pueden los skills reemplazar la documentacion de estandares de codigo?
Los skills complementan los estandares de codificacion pero no los reemplazan. Un skill es una codificacion ejecutable de estandares que la IA sigue durante la generacion. Sin embargo, la documentacion de estandares cumple propositos adicionales: incorporar desarrolladores humanos, explicar el razonamiento detras de las decisiones y cubrir escenarios que la generacion con IA no aborda (procedimientos de despliegue, respuesta a incidentes, configuracion de monitoreo). La configuracion ideal es un documento de estandares vivo que sirva como fuente de verdad, con skills derivados de el como mecanismo de aplicacion para codigo generado por IA.
¿Como se versionan y comparten skills en un equipo?
Los skills son archivos de texto que pertenecen al control de versiones junto a tu codebase. Almacenalos en un directorio .claude/skills/ en la raiz del repositorio. Cada skill tiene su propio subdirectorio con un archivo SKILL.md que contiene las instrucciones. Debido a que los skills son texto plano, se benefician del mismo proceso de revision que el codigo: los cambios pasan por pull requests, los miembros del equipo discuten modificaciones, y el historial de git rastrea como evolucionan las decisiones arquitectonicas con el tiempo. Los equipos con multiples repositorios pueden mantener un repositorio compartido de skills que los proyectos individuales referencien.
¿Que ocurre cuando la IA se desvia de las instrucciones del skill?
La desviacion es rara con Opus 4.6 pero no imposible, especialmente con definiciones de skills extremadamente largas o contradictorias. Cuando ocurre, la desviacion tipicamente es visible en la estructura de salida: un directorio faltante, un archivo fusionado o una direccion de importacion incorrecta. La solucion es el refinamiento iterativo del skill. Identifica que instruccion se omitio, reformulala con mayor enfasis o muevela antes en el documento del skill (los modelos dan mayor prioridad a instrucciones encontradas antes), y regenera. Con el tiempo, los skills se estabilizan a medida que se abordan los casos extremos.
¿Son los skills transferibles entre modelos de IA?
Los skills son documentos de texto agnosticos al modelo, por lo que pueden usarse con cualquier modelo que siga instrucciones. Sin embargo, la fidelidad de ejecucion varia significativamente. Un skill escrito para Opus 4.6 que usa mas de 30 restricciones interactuantes puede funcionar impecablemente con Opus pero producir cumplimiento parcial con otros modelos. Al transferir skills, prueba con el modelo objetivo y simplifica restricciones si es necesario. Las decisiones arquitectonicas centrales en el skill siguen siendo validas independientemente de que modelo las ejecute; solo el nivel de complejidad de restricciones puede necesitar ajuste.
Conclusion
Los skills de desarrollo representan el eslabon perdido entre la velocidad de generacion de codigo con IA y el rigor de ingenieria. Codifican las decisiones arquitectonicas, estandares de codificacion y patrones estructurales que definen un codebase bien mantenido en plantillas reutilizables que Opus 4.6 sigue con alta fidelidad. El resultado es codigo generado que llega pre-estructurado, con nomenclatura consistente y arquitectonicamente solido, reduciendo la carga de revision sobre los desarrolladores expertos al eliminar las preocupaciones estructurales del alcance de revision por completo. Pero la capa de revision experta permanece esencial. Los skills manejan las dimensiones mecanicas de la calidad del software. La correccion de logica de negocio, la validacion de limites de seguridad, los casos extremos especificos del dominio y el ajuste de rendimiento bajo patrones de carga del mundo real requieren juicio humano que ninguna plantilla de instrucciones puede reemplazar. Los equipos mas efectivos usan skills para manejar el 60-70% del codigo que es scaffolding estructural, luego concentran su revision experta en el 30-40% que determina si el software realmente resuelve el problema correcto de manera correcta. Comienza con un skill para tu patron mas repetido. Un unico skill de clean architecture aplicado a tu framework principal demostrara el valor dentro de tu primer sprint, y a partir de ahi, la practica escala naturalmente a medida que tu equipo identifica los patrones que vale la pena codificar.
Etiquetas
Compartir este artículo
Suscríbete
Recibe los últimos artículos directamente en tu bandeja de entrada.



Deja un comentario